Abstract
Prompt-based learning has been demonstrated as a compelling paradigm contributing to large language models' tremendous success (LLMs). Inspired by their success in language tasks, existing research has leveraged LLMs in embodied instruction following and task planning. In this work, we tackle the problem of training a robot to understand multimodal prompts, interleaving vision signals with text descriptions. This type of task poses a major challenge to robots' capability to understand the interconnection and complementarity between vision and language signals. In this work, we introduce an effective framework that learns a policy to perform robot manipulation with multimodal prompts from multi-task expert trajectories. Our methods consist of a two-stage training pipeline that performs inverse dynamics pretraining and multi-task finetuning. To facilitate multimodal understanding, we design our multimodal prompt encoder by augmenting a pretrained LM with a residual connection to the visual input and model the dependencies among action dimensions. Empirically, we evaluate the efficacy of our method on the VIMA-BENCH and establish a new state-of-the-art (10% improvement in success rate). Moreover, we demonstrate that our model exhibits remarkable in-context learning ability.
Challenges in Multimodal Robotic Learning
- The vision signals in the prompt can represent target objects, delineate a specific sub-goal, or offer in-context demonstrations.
- The robot must understand the underlying transition dynamics suggested by the multimodal prompts before tackling the overall task objective
- The robot should infer state transitions from language instructions, and deducing actions from image demonstrations, a concept known as inverse dynamic prediction.
- However, imitation learning falls short in teaching robots to predict inverse dynamics, as future observations are often masked out when training to predict actions from current and history observations
Inverse Dynamic Pretraining
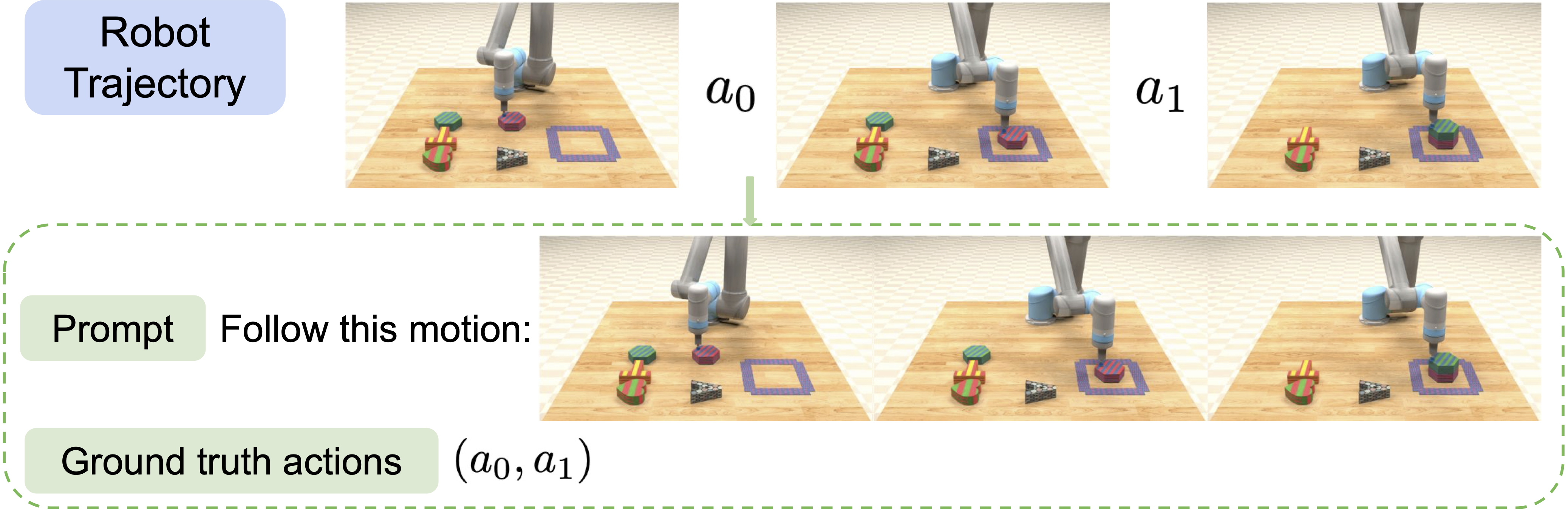
- We make a novel observation that every robot trajectory itself can be reformulated into a motion following task.
-
Given any sequence of robot trajectory ωT = (o0, a0, o1, …, aT-1, oT), we can always create a task with the prompt qpretrain = (Follow this motion: o0, …, oT) and ground-truth actions (a0, …, aT-1).
Model Architecture
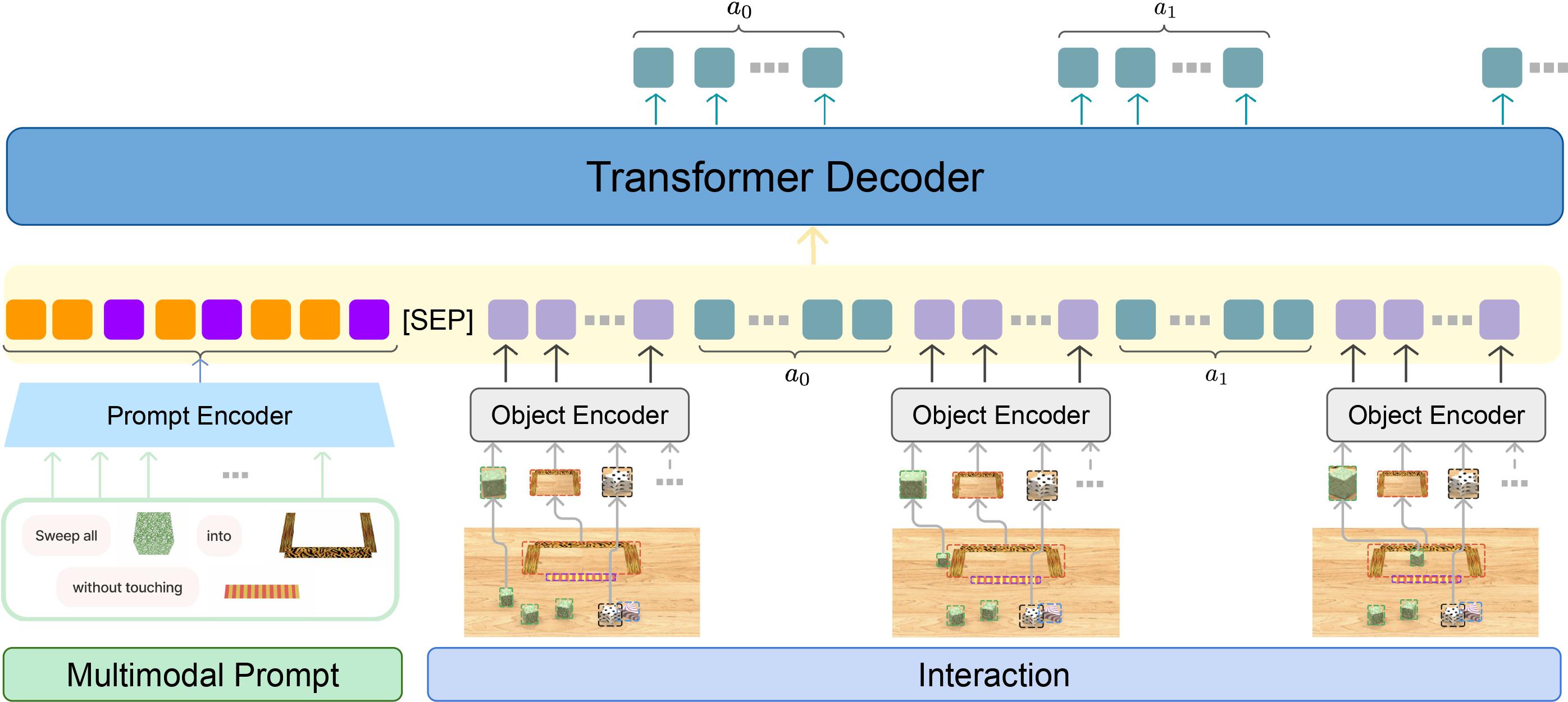
Model Architecture of our MIDAS. Our model adopts a decoder-only architecture. The multimodal prompt embeddings are concatenated with history observation and action tokens. We model each action dimension as an individual token and predict them auto-regressively.
Multimodal Prompt Encoder
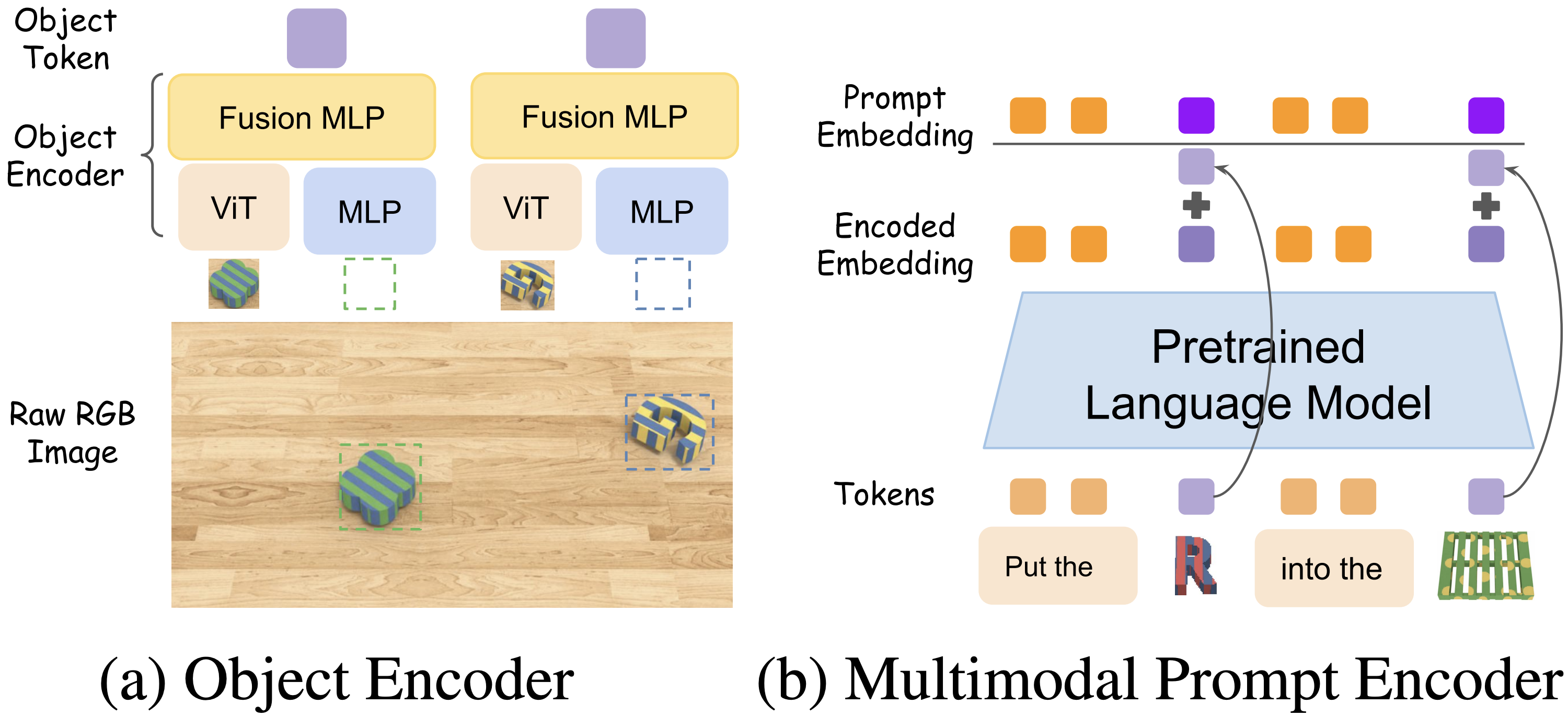
(a) We adopt the Object Encoder proposed in VIMA, which consists of a ViT that extracts visual embedding from cropped object images and a MLP that encodesbounding boxes. The two embeddings are concatenated before passing through a Fusion MLP to get the object tokens. (b) Our Multimodal Prompt Encoder adds a residual connection from the input object tokens to the pretrained LM output.
Modeling the Dependency Among Each Action Dimension
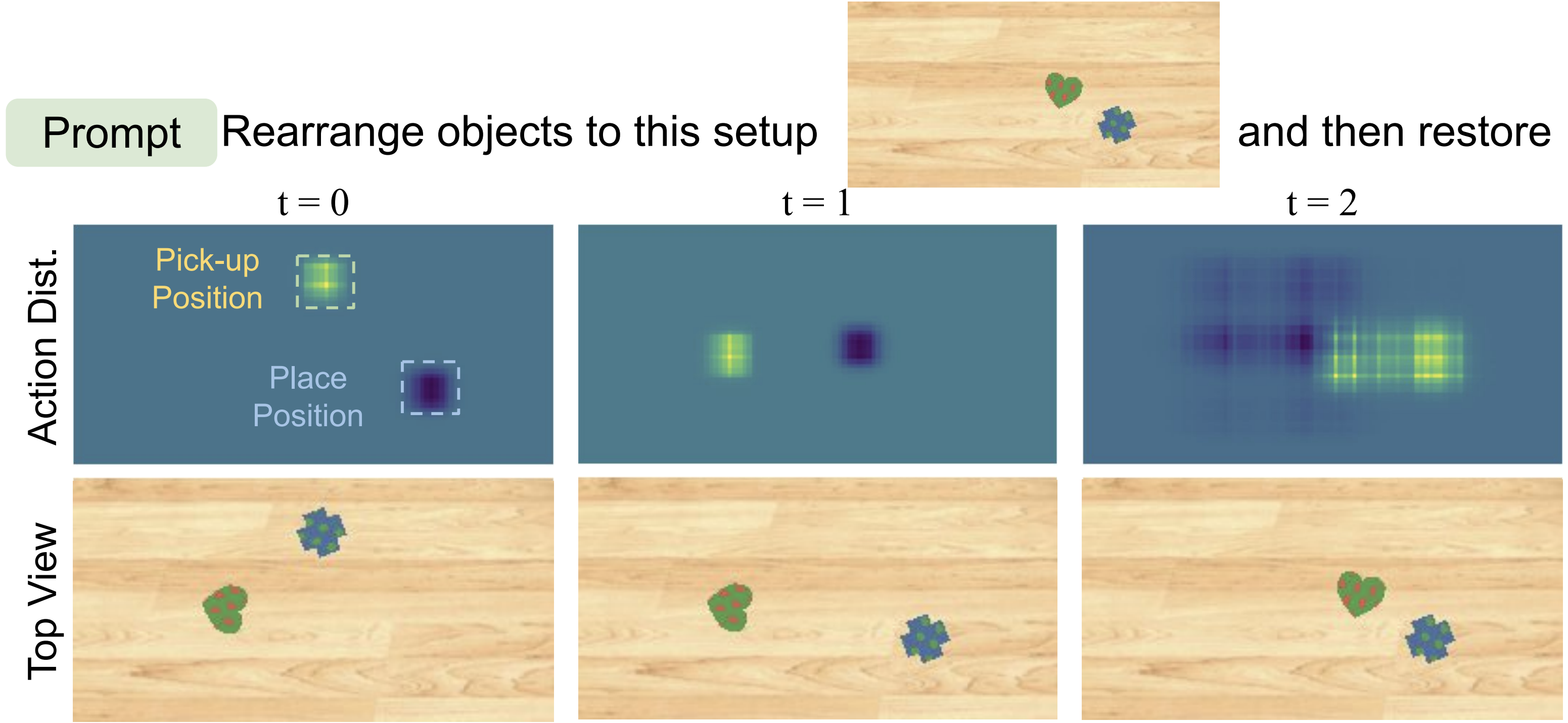
Independently predicting each action dimension can be problematic. Consider the example above, the robot should move either the heart or the cross block. As the policy predicts each action dimension independently, different dimensions do not consistently manipulate the same object, resulting in a task failure.
Experiment Results
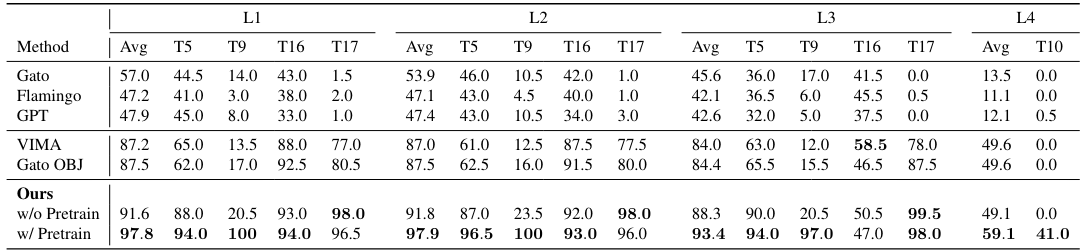
We compared our methods with baseline approaches on the VIMA-BENCH across all four evaluation levels. “Avg” represents the average success rate for all tasks within an evaluation level. To determine the success rate for each method, we sampled 200 episodes from every task. Our methods significantly outperform baseline methods and establish a new state-of-the-art performance on the VIMA-BENCH.
Acknowledgement
This project would not be possible without the wonderful prior work VIMA-BENCH.
BibTeX
@misc{li2024midas,
title={Mastering Robot Manipulation with Multimodal Prompts through Pretraining and Multi-task Fine-tuning},
author={Jiachen Li and Weixi Feng and Wenhu Chen and William Yang Wang},
journal={Proceedings of the 41st International Conference on Machine Learning},
year={2024}
}